PointNet:The Pioneer of Point Cloud Deep Learning
Point Cloud Data
Point cloud data refers to a set of vectors in a 3D coordinate system. A normal point cloud object is usually with 2D shape (n, 3+X), where n is the number of points, 3 stands for 3D coordinates and X contains other features like color and orientation.
Point cloud data has the following characteristics:
- Permutation Invariance: A point cloud object with $n$ points can be permuted in $n!$ different orders, but the point set always represents the same object no matter how they are permuted.
- Transformation Invariance: Classification and segmentation outputs should be unchanged if the object undergoes rigid transformations.
- Interaction among points: The points are from a space with a distance metric which means that points are not isolated.
To use point cloud data, Volumetric CNNs transform point data into volumes, but is constrained by its resolution due to data sparsity and computation cost of 3D convolution; Multiview CNNs try to render 3D point cloud or shapes into 2D images and apply 2D conv nets to
classify them, which is nontrivial to extend them to scene understanding or other 3D tasks such as point classification and shape completion.
PointNet
PointNet was first proposed in 2016 and is the first to directly use point cloud data for deep learning.It takes raw point cloud data as input for classification and segmentation.
PointNet Architecture
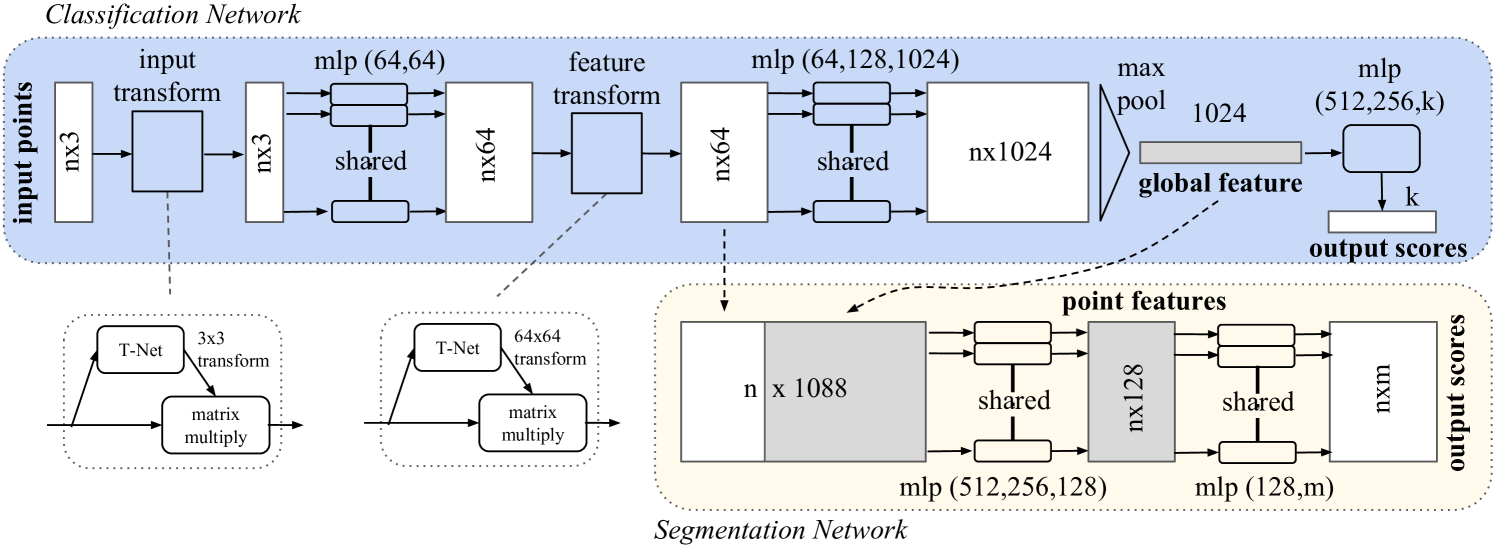
The classification network takes n points as input, applies input and feature transformations, and then aggregates point features by max pooling. The output is classification scores for k classes. The segmentation network is an extension to the classification net. It concatenates global and local features and outputs per point scores. “mlp” stands for multi-layer perceptron, numbers in bracket are layer sizes. Batchnorm is used for all layers with ReLU. Dropout layers are used for the last mlp in classification net.
By analyzing the architecture of PointNet above, we can divide PointNet into 2 stages: input & feature transform and certain task output. Noticeably, for each point cloud object, the number of points is usually different, so we need to sample a fixed number of points at first.Here we use a method called Farthest Point Sampling (FPS), which iteratively samples the farthest point and performs distance updating.
Given input points ${x_1, x_2, …, x_n}$, FPS choose a subset of points ${x_{i_1} , x_{i_2} , …, x_{i_m}}$, such that $x_{i_j}$ is the most distant point (in metric distance) from the set ${x_{i_1} , x_{i_2} , …, x_{i_{j-1}}}$ with regard to the rest points. Compared with random sampling, it has better coverage of the entire point set given the same number of centroids. FPS sampling strategy generates receptive fields in a data dependent manner.
Here’s the code of FPS:
1 | |
Task output
In order to analyze how to deal with permutation invariance more intuitively, we first discuss. As show in Fig.2, classfication head takes the output of feature transform with shape (n, 64) and the feature dimension is increased to 1024 by a mlp. After that, a max pool is excuted on dimension of number of points and we get global feature for each point with the length of 1024. Due to characteristics of max pool, the feature is permutation invariant. For segmantation, global feature is repeated by n times and concatenated with local feature (output of feature transform) to get point-wise feature.
Here’s the main code of this stage:
1 | |
Where stn will be explained in next section.
Input & feature transform
For input transform, the PointNet model takes input with shape of (n, 3) and use a learnable T-Net to get an affine transformation matrix, then multiply the matrix and point cloud data. This stage is mainly to align the points to deal with the transformation invariance.
Here’s the code of T-Net (STN3d is similar):
1 | |
It is not difficult to find that T-Net also obtains permutation invariant affine transformation matrix through max pool. Transformation matrix in the feature space has much higher dimension than the input transform matrix, which greatly increases the difficulty of optimization, so the authors add a regularization term $L_{reg}=||I - AA^T||^2_F$ to make the transformation matrix A of the feature space as close to the orthogonal matrix as possible.