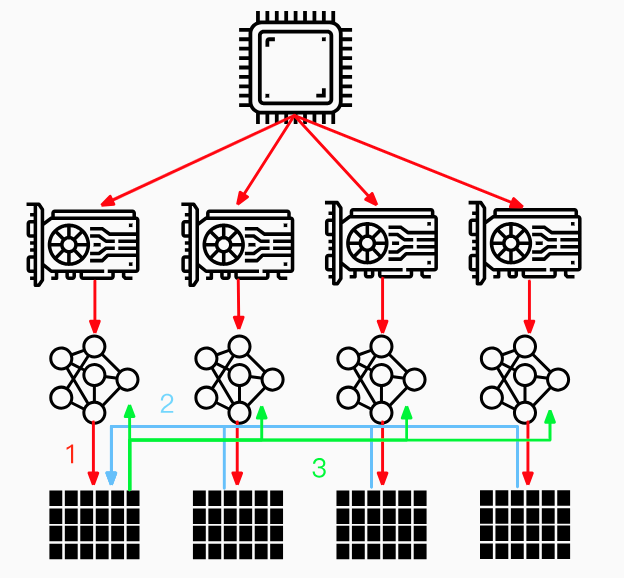
While iterating: 1. Scatter batch to mini-batch and distribute them across given GPUs 2. Replicate and broadcast model and paramaters from master GPU to other GPUs 3. Forwardoneach GPU and gather results on master GPU 4. Compute loss and distribute toeach GPU 5. Complete backpropagation to calculate the gradient 6. Gather gradient oneach GPU and update parameters with average gradient ...
Analysis
Unbalanced load: more load on master GPU
Communication overhead: Assuming that there are $K$ GPUs, the total communication volume is $p$, and the communication bandwidth is $b$. Then using the Parameter Server algorithm, it takes a total of time $T=2(K-1)\frac{p}{b}$. $T$ increases with the increase of $K$.
Single process: A Python process can only use one CPU kernel, that is, when a single-core multi-thread is concurrent, only one thread can be executed. Considering multi-core, multi-core and multi-threading may cause thread thrashing to cause waste of resources, so if Python wants to take advantage of multi-core, it is best to use multi-process.
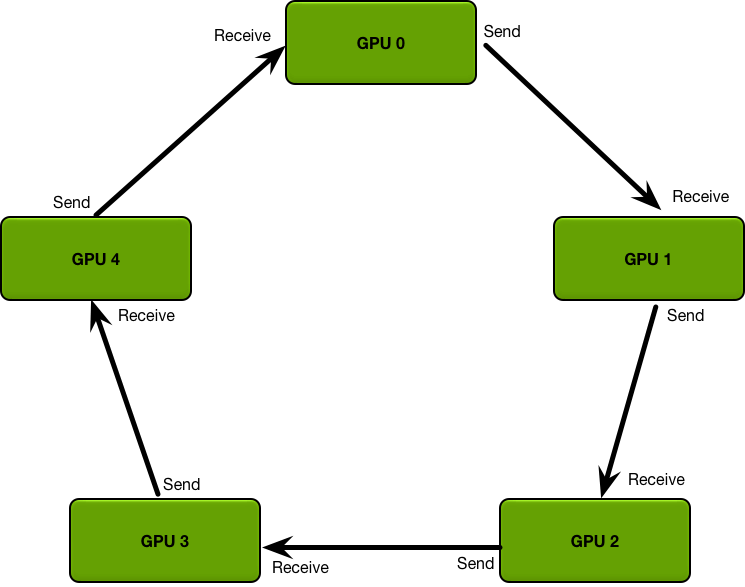
Fig.2 Ring Allreduce
The GPUs in a ring allreduce are arranged in a logical ring. Each GPU should have a left neighbor and a right neighbor; it will only ever send data to its right neighbor, and receive data from its left neighbor.
The algorithm proceeds in two steps: first, a scatter-reduce, and then, an allgather. In the scatter-reduce step, the GPUs will exchange data such that every GPU ends up with a chunk of the final result. In the allgather step, the GPUs will exchange those chunks such that all GPUs end up with the complete final result.
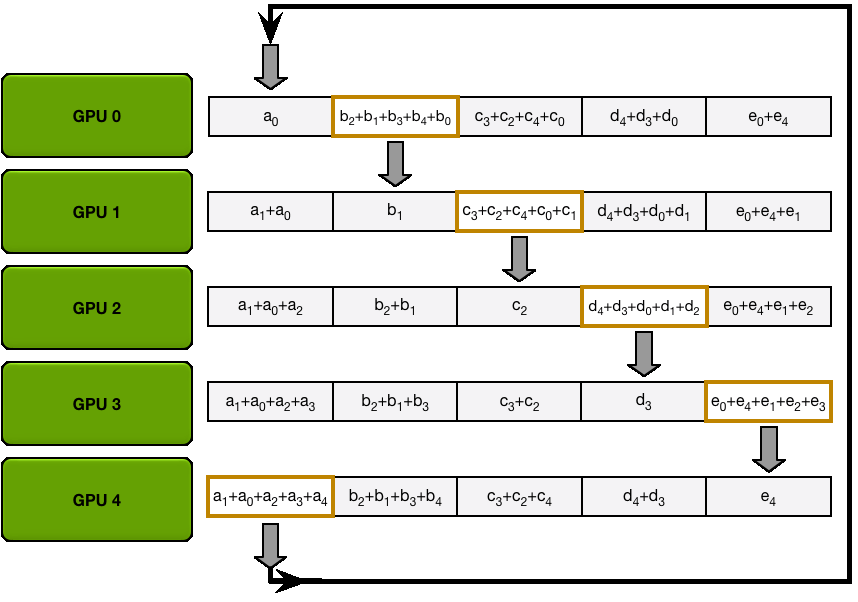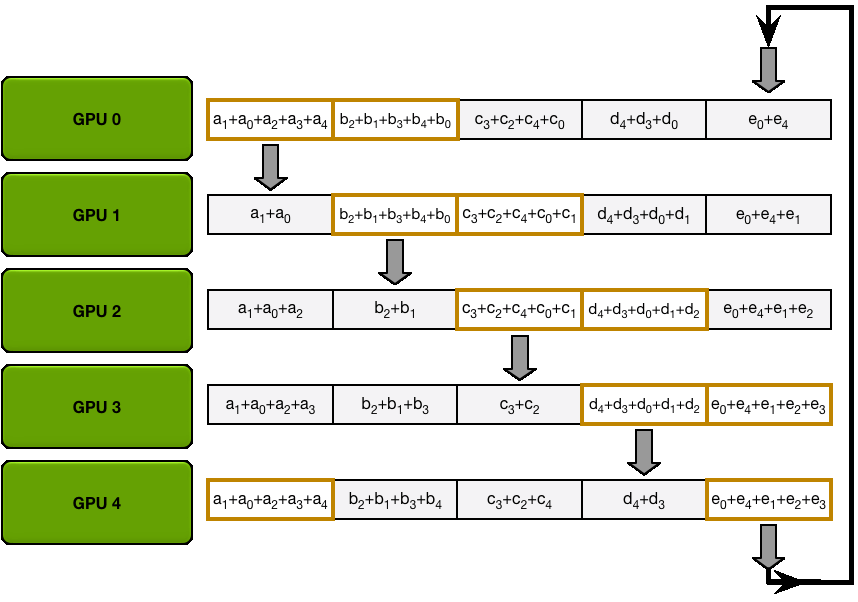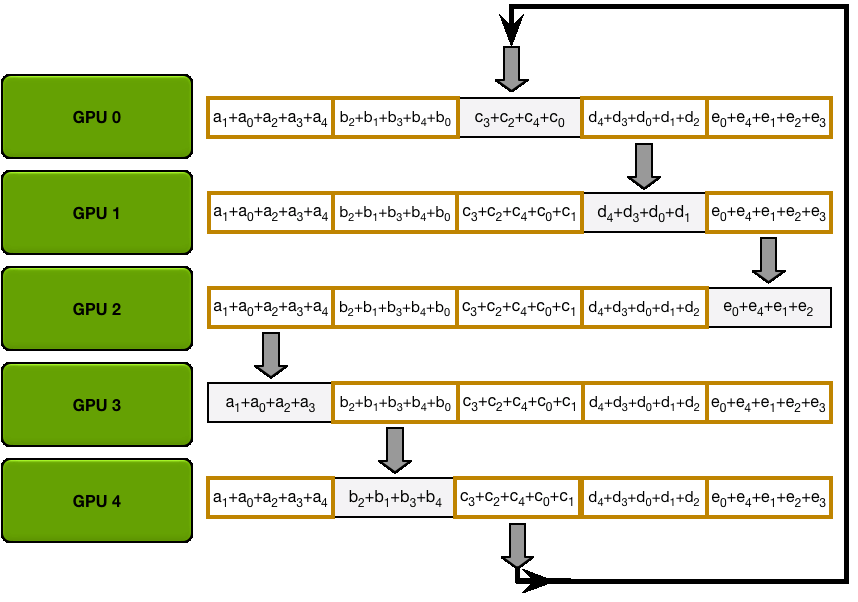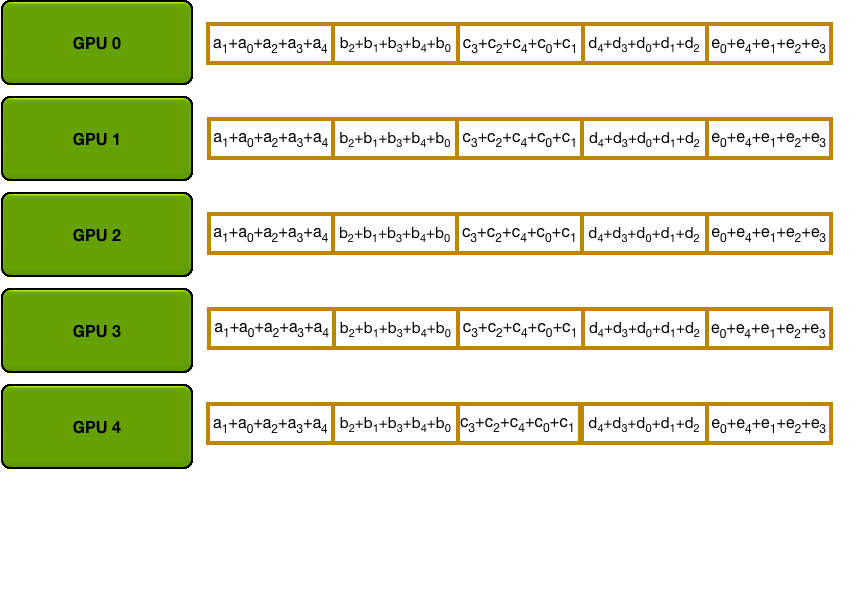
Scatter-Reduce
Fig.3 Scatter-Reduce
The parameters are divided into $K$ chunks, and adjacent GPUs pass different parameters. After passing $K-1$ times, the accumulation of a each parameter can be obtained on different GPUs.
Allgather
Fig.4 Allgather
After getting the accumulation of each parameter, do another transfer and synchronize to all GPUs.
Communication Overhead
Assuming that there are $K$ GPUs, the total communication volume is $p$, and the communication bandwidth is $b$. Then using the Ring Allreduce, The amount of communication per GPU is $\frac{p}{K}$. It takes a total of time $T=2(K-1)\frac{\frac{p}{K}}{b} = (1 - \frac{1}{K})* 2\frac{p}{b} \approx 2\frac{p}{b}$ ,which is approximately independent of $K$.
Procedure
1 2 3 4 5 6 7 8
Divide parameters into chunks and init state. # Each GPU receives a parameter chunk, and these parameters are replicated on that GPU. # Each GPU has the full model structure on it, but only processes its own chunk of parameters. # A process with a rank of 0 will broadcast the network initialization parameters to every other process to ensure that the models in each process have the same initialization value. While iterating : 1. Get non-repeating batch input from distributed sampler on each GPU 2. Forward, compute loss and backpropogation to compute gradient of each chunk 3. Ring Allreduce