Tokenization And Embedding
Tokenization And Embedding
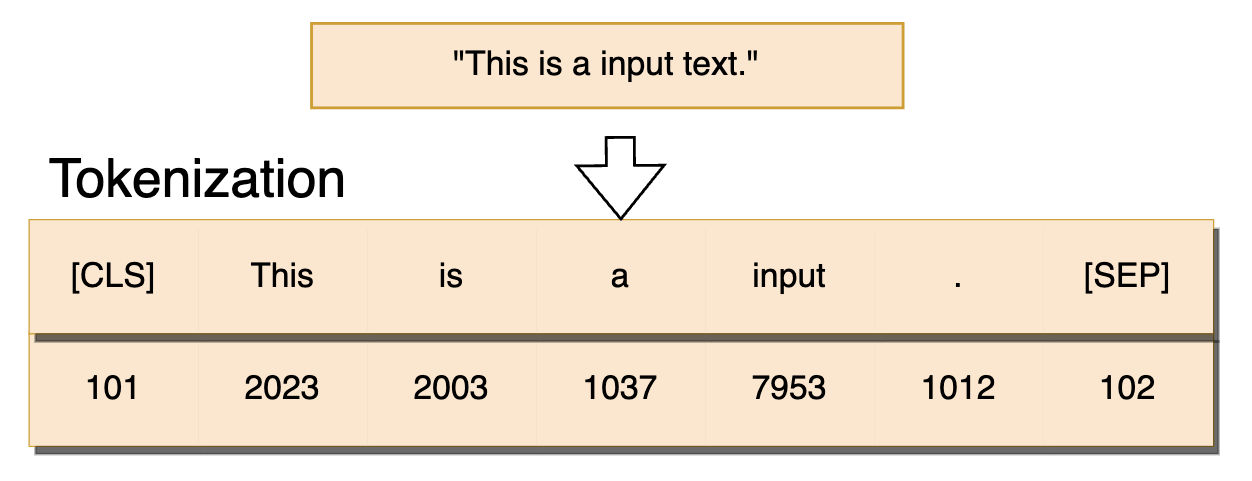
Tokenization
1 | |
Byte-Pair Encoding (BPE)
Byte-Pair Encoding (BPE) was introduced in Neural Machine Translation of Rare Words with Subword Units. BPE relies on a pre-tokenizer that splits the training data into words. Pretokenization can be as simple as space tokenization. More advanced pre-tokenization include rule-based tokenization which uses Moses for most languages, or GPT which uses Spacy and ftfy, to count the frequency of each word in the training corpus.
After pre-tokenization, a set of unique words has been created and the frequency with which each word occurred in the training data has been determined. Next, BPE creates a base vocabulary consisting of all symbols that occur in the set of unique words and learns merge rules to form a new symbol from two symbols of the base vocabulary. It does so until the vocabulary has attained the desired vocabulary size. Desired vocabulary size is a hyperparameter to define before training the tokenizer.
BPE is a word segmentation algorithm based on statistics, which is highly dependent on the corpus. If the corpus is small, the effect is generally not good.
Procedure
- Count all occurrences of words in the input and add a word terminator
</w>after each word - Split all words into individual characters
- Combine the most frequently occurring words
1
{'a':16, 'b': 12, 'c': 8} -> {'ab':12, 'a': 4, 'c': 8} - Iterate 3. repeatedly until the vocabulary size is equal to desired vocabulary size or the frequency of the next character pair is 1.
Encode
- Sort the words in the vocabulary according to their length, from long to short
- For each word in the corpus, traverse the sorted vocabulary, determine whether the word/subword (subword) in the vocabulary is a substring of the string, if it matches, output the current subword, and Continue to iterate over the remaining strings of words.
- If after traversing the vocabulary, there is still a substring in the word that is not matched, then we replace it with a special subword, eg.
<unk>
Decode
Corpus decoding is to put all the output subwords together until the end is <\w>.
Word-Piece
Word-Piece is very similar to BPE. BPE uses the most frequently occurring combined constructor vocabulary, while Wordpiece uses the most frequently occurring $\frac{P(AB)}{P(A)P(B)}$ combined constructor vocabulary.
Unigram
Different from BPE or Word-Piece, Unigram’s algorithm idea is to start from a huge vocabulary, and then gradually delete the trim down vocabulary until the size meets the predefined size.
The initial vocabulary can use all the words separated by the pre-tokenizer, plus all high-frequency substrings.
The principle of removing words from the vocabulary each time is to minimize the predefined loss. During training, the formula for calculating loss is:
$$
Loss = - \sum_{i=1}^{N}\log \left(\sum_{x\in S(x_i)}p(x)\right)
$$
Assume that all the words in the training document are $x_1,x_2,…,x_N$, and the method of tokenizing each word is a set $S(x_i)$.
When a vocabulary is determined, the set $S(x_i)$ of tokenize methods for each word is determined, and each method corresponds to a probability $p(x)$.
If some words are deleted from the vocabulary, the set of tokenize types of some words will be reduced, and the summation items in log(*) will be reduced, thereby increasing the overall loss.
The Unigram algorithm will pick out 10%~20% of the words that make the loss increase the least from the vocabulary each time and delete them. Generally, the Unigram algorithm will be used in conjunction with the SentencePiece algorithm.
Sentence-Piece
Sentence-Piece is mainly used for multilingual models, and it does two important transformations:
- Encode characters in unicode mode, convert all input (English, Chinese and other languages) into unicode characters, and solve the problem of different multi-language encoding methods.
- Encode spaces into
_, such as'New York'will be converted into['_', 'New', '_York'], this is also to be able to deal with multilingual problems.
It treats a sentence as a whole and breaks it down into fragments without retaining the concept of natural words. Generally, it treats spaces as a special character, and then uses BPE or Unigram algorithm to construct a vocabulary.
Embedding
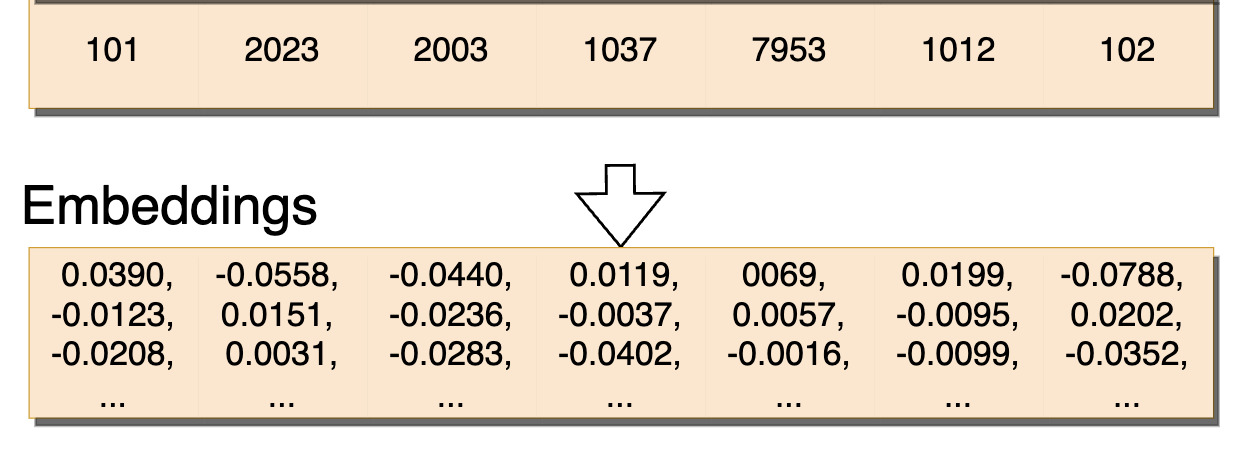
For example, suppose the Embedding matrix is
1 | |
Then
1 | |