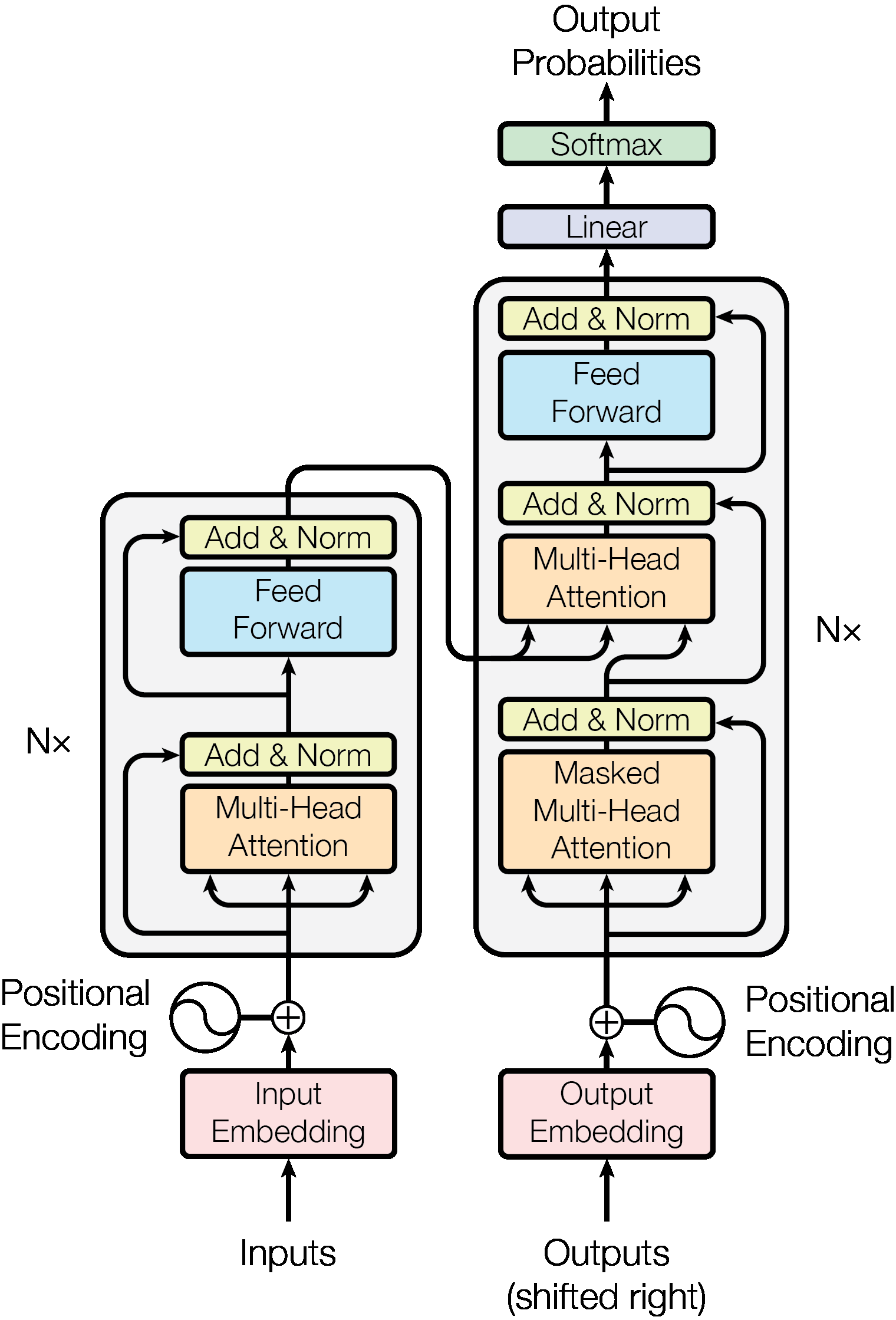
Transformer was firsr used for machine translation with an an encoder-decoder structure, see Fig.1. The input (source) and output (target) sequence embeddings are added with positional encoding before being fed into the encoder and the decoder that stack modules based on self-attention.
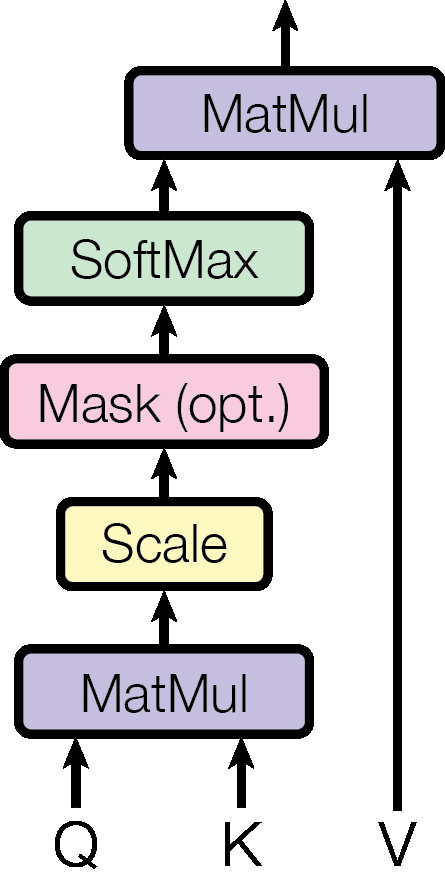
Scaled Dot-Product Attention
Fig.2 Scaled Dot-Product Attention
Transformer uses “Scaled Dot-Product Attention”. The input consists of queries $Q$ and keys $Q$ of dimension $d_k$, and values $V$ of dimension $d_v$. This attention computes the dot products of the query with all keys, divide each by $\sqrt{d_k}$ and apply a softmax function to obtain the weights on the values. The scaling factor $d_k$ is used to counteract the effect that for large values of $d_k$, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. $$ \text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V $$
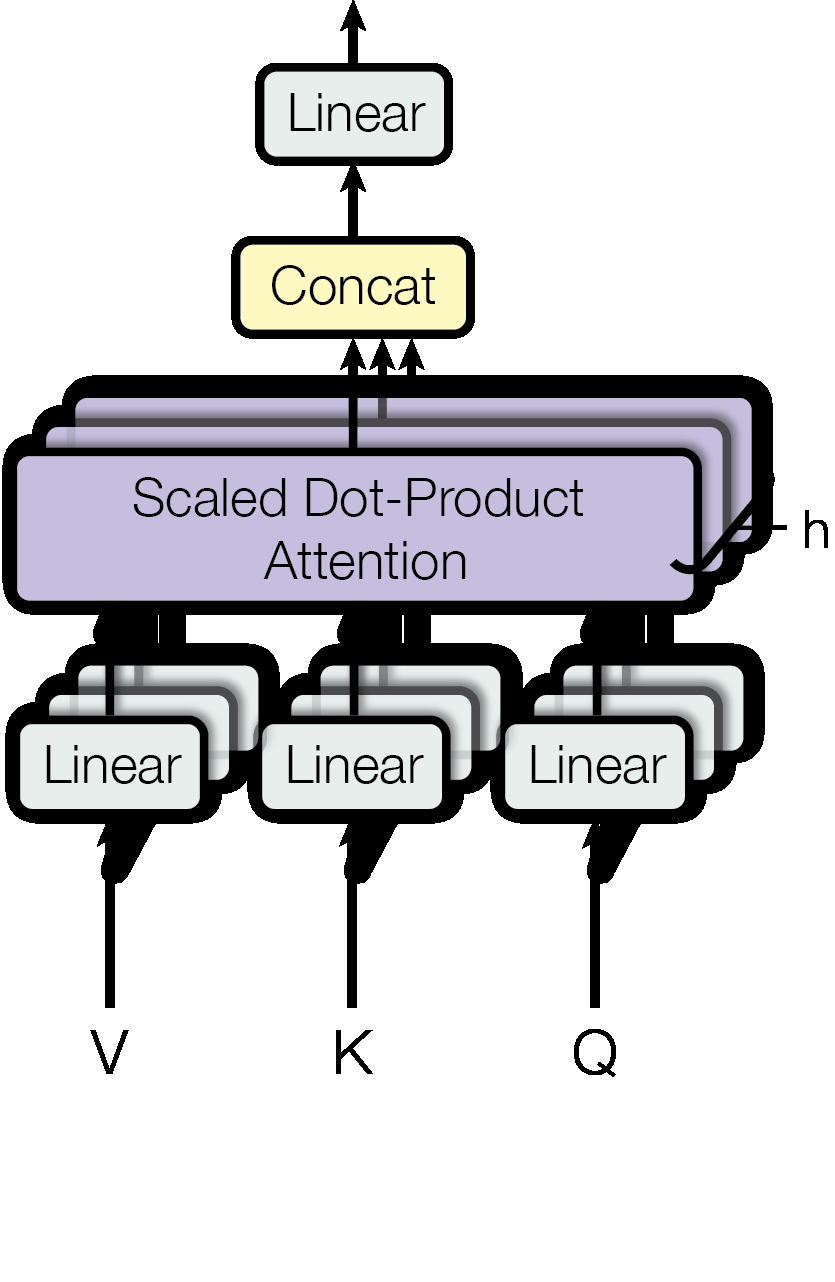
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. Instead of performing a single attention function with $d_{model}$-dimensional keys, values and queries, it’s beneficial to linearly project the queries, keys and values $h$ times with different, learned linear projections to $d_k, d_k$ and $d_v$ dimensions, respectively. On each of these projected versions of queries, keys and values, the attention function is performed in parallel, yielding $d_v$-dimensional output values. These are concatenated and once again projected, resulting in the final values. In this work, $d_k=d_v=d_{model} / h$
Since transformer contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, “positional encodings” as added to the input embeddings. For transformer, the authors use sine and cosine functions of different frequencies:
As the two embedding layers and the pre-softmax linear transformation share the same weight, the output of embedding layer should be multiplied by $d_{model}$ (because the pre-softmax linear layer usually inited by xaiver init)
The encoder is composed of a stack of identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network. A residual connection is employed around each of the two sub-layers, followed by layer normalization. That is, the output of each sub-layer is $\text{LayerNorm}(x+\text{Sublayer}(x))$, where $\text{Sublayer}(x)$ is the function implemented by the sub-layer itself.
Dropout is applied to the output of each sub-layer, before it is added to the sub-layer input and normalized. In addition, dropout is applied to the sums of the embeddings and the positional encodings in both the encoder and decoder stacks.
src = self.drop(self.pos_encode(self.ebd(src))) for blk in self.blks: src = blk(output, src_mask)
return src
Decoder
The decoder is also composed of a stack of identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. The self-attention sub-layer in the decoder stack is modified to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position $i$ can depend only on the known outputs at positions less than $i$.