BERT:Bidirectional Encoder Representations from Transformers
Input/Output Representations
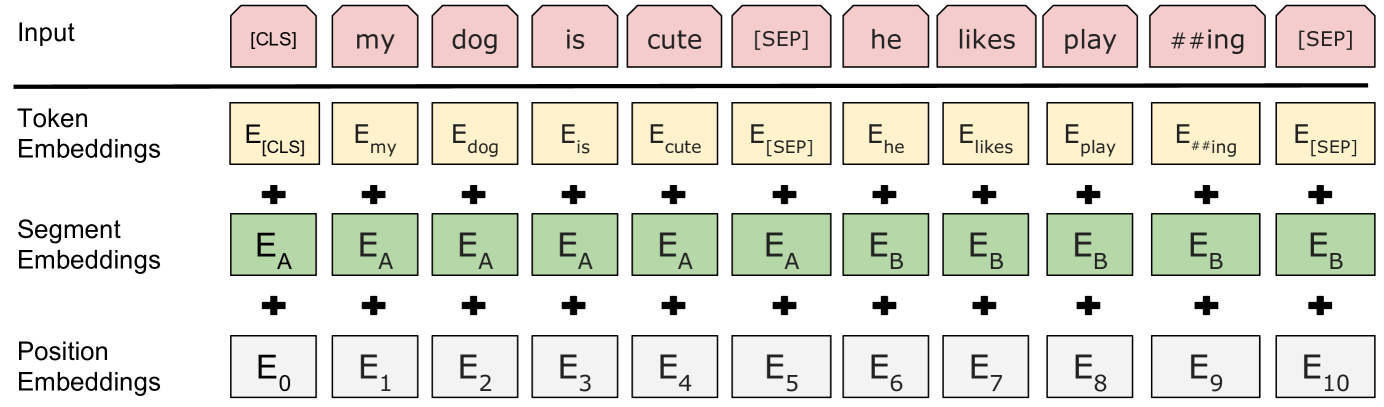
For handling a variety of down-stream tasks, the input representation of BERT is able to unambiguously represent both a single sentence and a pair of sentences in one token sequence. Throughout this work, a “sentence” can be an arbitrary span of contiguous text, rather than an actual linguistic sentence. A “sequence” refers to the input token sequence to BERT, which may be a single sentence or two sentences packed together.
The first token of every sequence is always a special classification token [CLS]. The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks. Sentence pairs are packed together into a single sequence and separated with a special token [SEP]. A learned embedding to every token is added to indicate whether it belongs to sentence A or sentence B. The input embeddings are the sum of the token embeddings, the segmentation embeddings and the position embeddings.. The model architecture of BERT is nearly the same as.
The Pytorch implementation is
1 | |
Masked Language Model
In order to train a deep bidirectional representation, BERT takes randomly masked sequences as input (those masked tokens are replaced by [MASK]) and then predicts those masked tokens. In this case, the final hidden vectors corresponding to the mask tokens are fed into an output softmax over the vocabulary.
Although this allows a bidirectional pre-trained model, a downside is that MLM creats a mismatch between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning. To mitigate this, those “masked” words are not always replaced by the actual [MASK] token. The training data generator chooses 15% of the token positions at random for prediction.
Assuming the unlabeled sentence is my dog is hairy and during the random masking procedure hairy is choosen to be masked.
- 80% of the time: Replace the word with the
[MASK]token, e.g.,my dog is hairy->my dog is [MASK] - 10% of the time: Replace the word with a random word, e.g.,
my dog is hairy->my dog is apple - 10% of the time: Keep the word unchanged, e.g.,
my dog is hairy->my dog is hairy. The purpose of this is to bias the representation towards the actual observed word.
The advantage of this procedure is that the Transformer encoder does not know which words it will be asked to predict or which have been replaced by random words, so it is forced to keep a distributional contextual representation of every input token. Additionally, because random replacement only occurs for 1.5% of all tokens, this does not seem to harm the model’s language understanding capability.
The Pytorch implementation is
1 | |
Next Sentence Prediction
Many important downstream tasks such as Question Answering (QA) and Natural Language Inference (NLI) are based on understanding the relationship between two sentences, which is not directly captured by language modeling. In order to train a model that understands sentence relationships, a binarized next sentence prediction task that can be trivially generated from any monolingual corpus is added. Specifically, when choosing the sentences A and B for each pre-training example, 50% of the time B is the actual next sentence that follows A (labeled as IsNext), and 50% of the time it is a random sentence from the corpus (labeled as NotNext)
The next sentence prediction task can be illustrated in the following examples.
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = 𝙸𝚜𝙽𝚎𝚡𝚝
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP]
Label = 𝙽𝚘𝚝𝙽𝚎𝚡𝚝
The Pytorch implementation is
1 | |
BERT Pytorch Implementation
Code of other modules are from this blog NOTE: The activation function of Point-wise Feed-Forward Networks in BERT is GELU instead of ReLU .
1 | |