The probability of the current state is only related to the previous moment, for example, considering Markov relationship $A \rightarrow B \rightarrow C$, then
For a neural network, If we want to sample from the Gaussian distribution $\mathcal{N}(\mu, \sigma^2)$, the result obtained is not differentiable. Thus, we can first sample $\epsilon$ from the standard distribution, and then get $\sigma * \epsilon + \mu$. Then the randomness is transferred to $\mu$ and $\sigma$, and and are used as part of the affine transformation network.
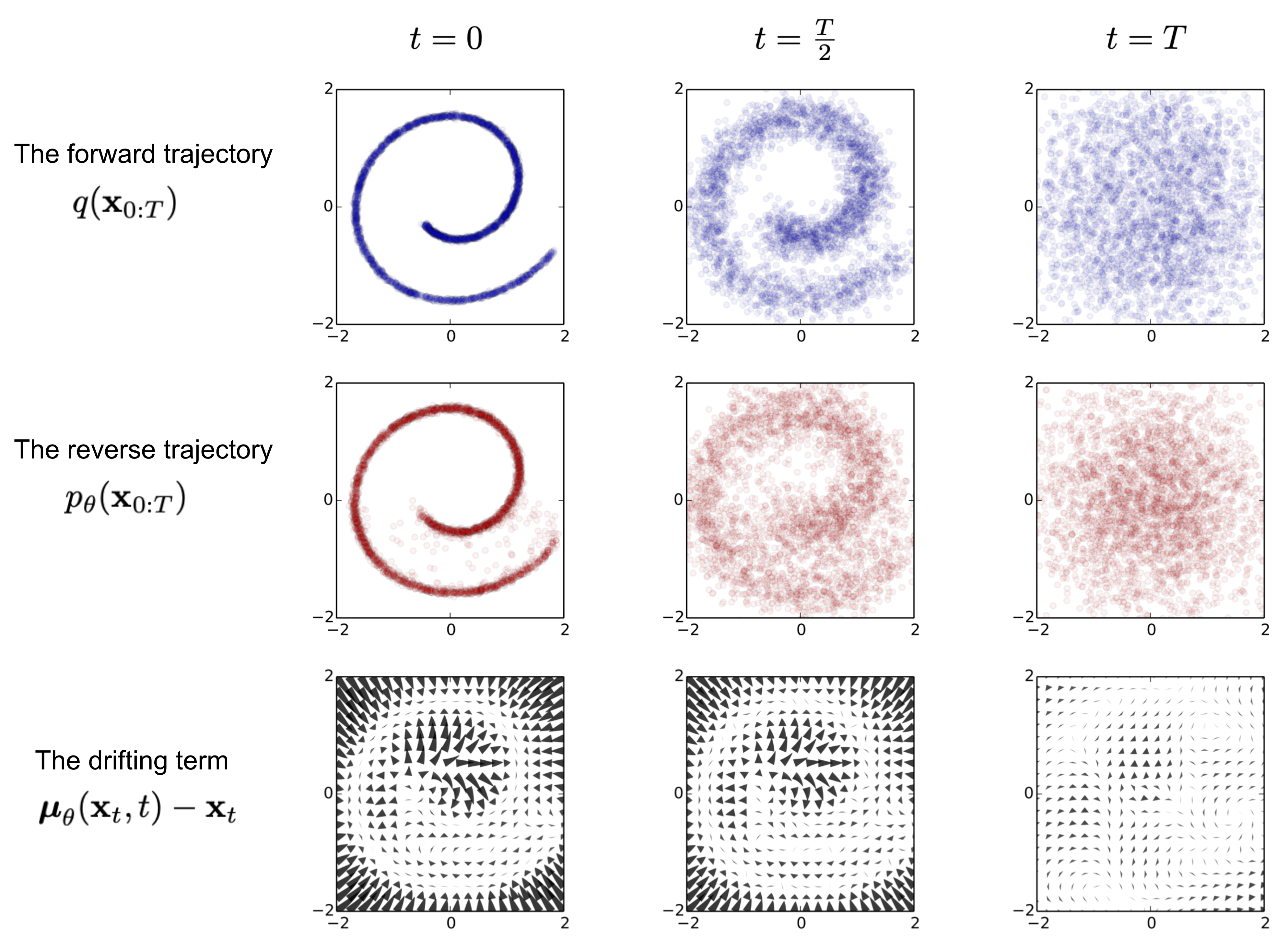
Forward Diffusion Process
Fig.1 Diffusion Probabilistic Model
Given a data point sampled from a real data distribution $\mathbf{x}_0 \sim q(\mathbf{x})$, let us define a forward diffusion process in which we add small amount of Gaussian noise to the sample in $T$ steps, producing a sequence of noisy samples $\mathbf{x}_1, \dots, \mathbf{x}_T$. The step sizes are controlled by a variance schedule ${\beta_t \in (0, 1)}_{t=1}^T$
The data sample $\textbf{x}_0$ gradually loses its distinguishable features as the step $t$ becomes larger. Eventually when $T \to \infty$, $\textbf{x}_T$ is equivalent to an isotropic Gaussian distribution.
Let $\alpha_t = 1 - \beta _t$ and $\bar{\alpha}_t = \prod _{i=1}^t \alpha_i$, then
(*) Recall that when we merge two Gaussians with different variance, $\mathcal{N}(\mathbf{0}, \sigma _1^2\mathbf{I})$ and $\mathcal{N}(\mathbf{0}, \sigma _2^2\mathbf{I})$, the new distribution is $\mathcal{N}(\mathbf{0}, (\sigma _1^2 + \sigma _2^2)\mathbf{I})$. Here the merged standard deviation is $\sqrt{(1 - \alpha _t) + \alpha _t (1-\alpha _{t-1})} = \sqrt{1 - \alpha _t\alpha _{t-1}}$.
Usually, we can afford a larger update step when the sample gets noisier, so $\beta _1 < \beta _2 < \dots < \beta _T$ and therefore $\bar{\alpha}_1 > \dots > \bar{\alpha}_T$.
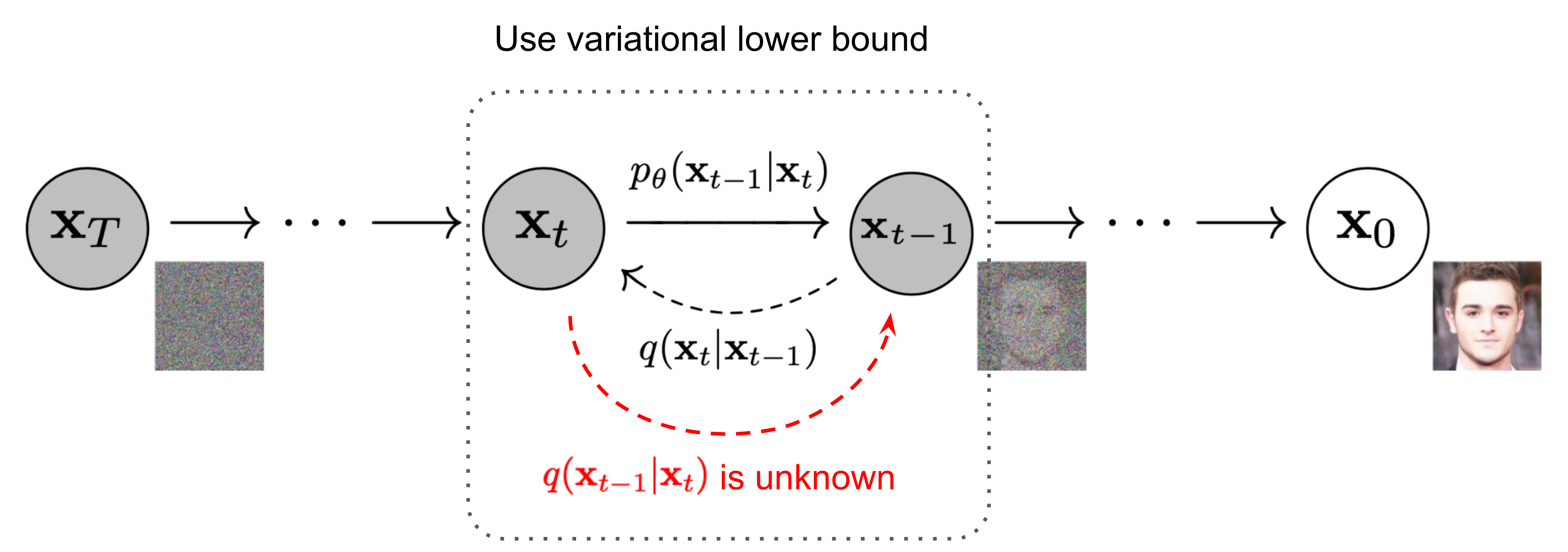
Reverse Diffusion Process
Fig.2 Diffusion Process
If we can reverse the above process and sample from $q(\mathbf{x}_{t-1} \vert \mathbf{x}_t)$ , we will be able to recreate the true sample from a Gaussian noise input, $\mathbf{x}_T \sim \mathcal{N}(\mathbf{0}, \mathbf{I})$ .
Note that if $\beta _t$ is small enough, $q(\mathbf{x}_t | \mathbf{x}_{t-1})$ will also be Gaussian.
Unfortunately, we cannot easily estimate $q(\mathbf{x}_t | \mathbf{x}_{t-1})$ because it needs to use the entire dataset and therefore we need to learn a model $p_{\theta}$ to approximate these conditional probabilities in order to run the reverse diffusion process.
where $C(\mathbf{x}_t, \mathbf{x}_0)$ is some function not involving $\mathbf{x}_{t-1}$ and details are omitted. Thus, following the standard Gaussian density function, the mean and variance can be parameterized as follows
As discussed above, we can represent $\mathbf{x}_0 = \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t)$ and plug it into the above equation and obtain