ATISS:Autoregressive Transformers for Indoor Scene Synthesis
Abstract
The ability to synthesize realistic and diverse indoor furniture layouts automatically or based on partial input, unlocks many applications, from better interactive 3D tools to data synthesis for training and simulation. In this paper, we present ATISS, a novel autoregressive transformer architecture for creating diverse and plausible synthetic indoor environments, given only the room type and its floor plan. In contrast to prior work, which poses scene synthesis as sequence generation, our model generates rooms as unordered sets of objects. We argue that this formulation is more natural, as it makes ATISS generally useful beyond fully automatic room layout synthesis. For example, the same trained model can be used in interactive applications for general scene completion, partial room rearrangement with any objects specified by the user, as well as object suggestions for any partial room. To enable this, our model leverages the permutation equivariance of the transformer when conditioning on the partial scene, and is trained to be permutation-invariant across object orderings. Our model is trained end-to-end as an autoregressive generative model using only labeled 3D bounding boxes as supervision. Evaluations on four room types in the 3D-FRONT dataset demonstrate that our model consistently generates plausible room layouts that are more realistic than existing methods. In addition, it has fewer parameters, is simpler to implement and train and runs up to 8x faster than existing methods.
Overview
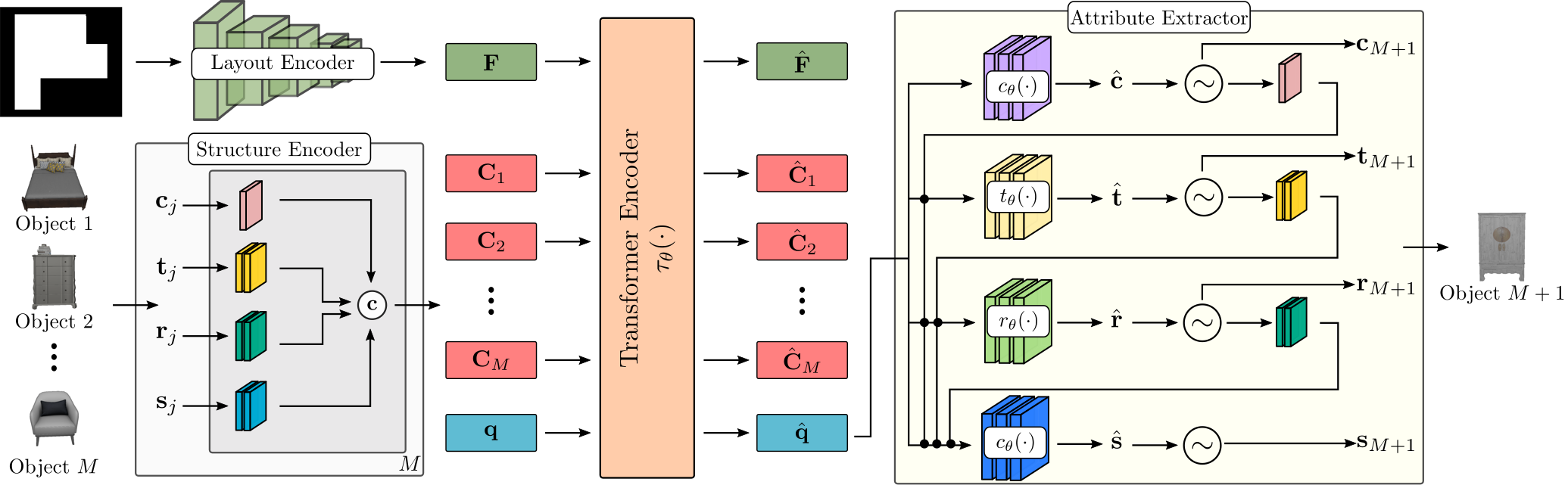
Suppose a scene comprises an unordered set of $M$ objects $\mathcal{O} = \{o_j\}^M_{j=1}$ and its floor shape ${\bf F}$. Objects in a scene are represented as labeled 3D bounding boxes and we model them with four random variables that describe their category, size, orientation and location, $o_j = \{ {\bf c}_j, {\bf s}_j, {\bf t}_j, {\bf r}_j\}$. The category ${\bf c}_j$ is modeled using a categorical variable over the total number of object categories in the dataset and the size ${\bf s}_j$, location ${\bf t}_j$ and orientation ${\bf r}_j$ are modelled with mixture of logistics distributions.:
where $\pi_k^{\alpha}$, $\mu_k^{\alpha}$ and $\sigma_k^{\alpha}$ denote the weight, mean and variance of the $k$-th ($K$ is a hyper parameter) logistic distribution used for modeling a certain attribute $\alpha$.
ATISS consists of four main components: (i) the layout encoder that maps the room shape to a feature representation ${\bf F}$, (ii) the structure encoder that maps the objects in the scene into per-object context embeddings ${\bf C} = \{C_j\}^M_{j=1}$ , (iii) the transformer encoder that takes ${\bf F}$, ${\bf C}$ and a query embedding ${\bf q}$ and predicts the features ${\bf \hat{q}}$ for the next object to be generated and (iv) the attribute extractor that predicts the attributes of the next object to be added in the scene.
Layout Encoder
The layout encoder is simply a ResNet-18 that extracts a feature representation ${\bf F}\in \mathbb{R}^{64}$ for the top-down orthographic projection of the floor.
Structure Encoder
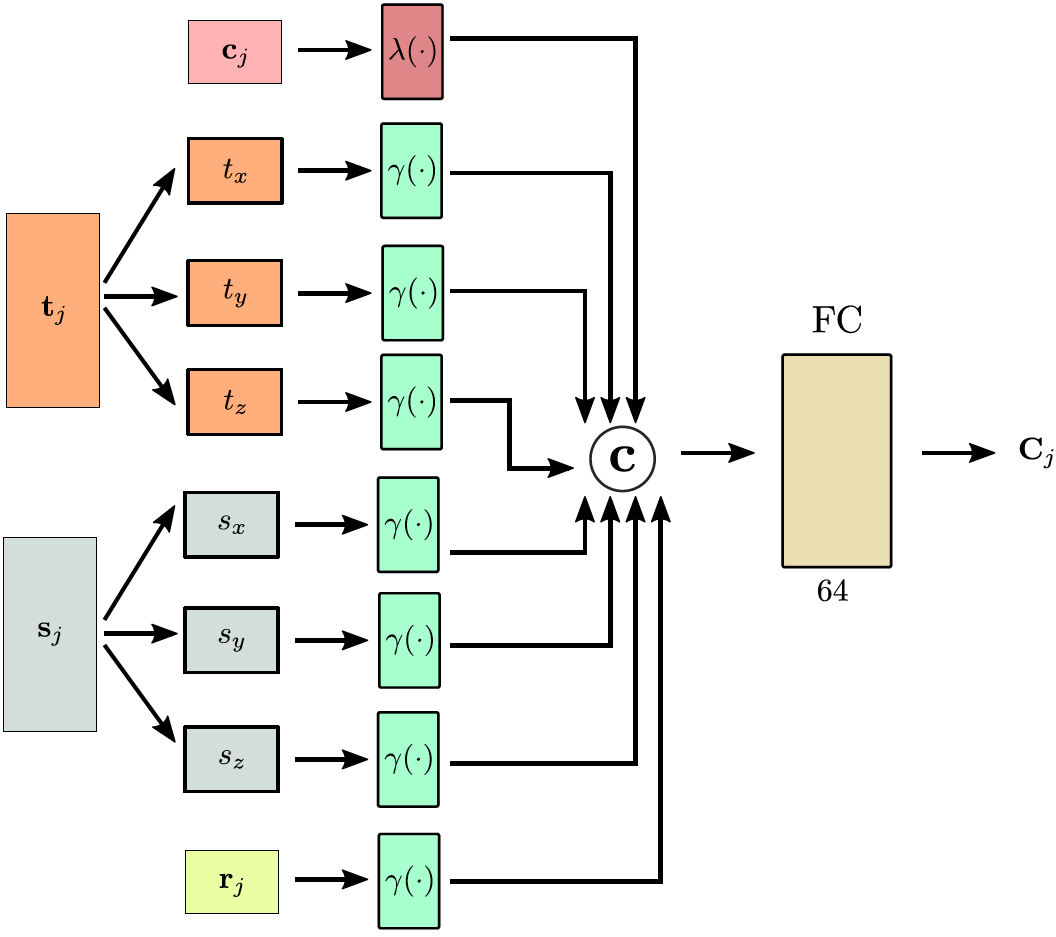
The structure encoder predicts the per-object context embeddings ${\bf C}_j$ conditioned on the object attributes. For the object category ${\bf c}_j$ , a learnable embedding $\lambda(\cdot)$ is used, whereas for the location ${\bf t}_j$ , the size ${\bf s}_j$ and orientation ${\bf r}_j$ , ATISS employs the cosine positional encoding $\gamma (\cdot)$ which is applied separately in each dimension of ${\bf t}_j$ and ${\bf s}_j$ .The output of each embedding layer are concatenated into an 512-dimensional feature vector, which is then mapped to the 64-dimensional per-object context embedding.
Transformer Encoder
The transformer consists of 4 layers with 8 attention heads. The queries, keys and values have 64 dimensions and the intermediate representations for the MLPs have 1024 dimensions. The input set of the transformer is ${\bf I = F} \cup \{C_j\}^M_{j=1} $, where $M$ denotes the number of objects in the scene and ${\bf q} \in \mathbb{R}^{64}$ is a learnable object query vector that allows the transformer to predict output features ${\bf \hat{q}} \in \mathbb{R}^{64}$ used for generating the next object to be added in the scene.
Attribute Extractor
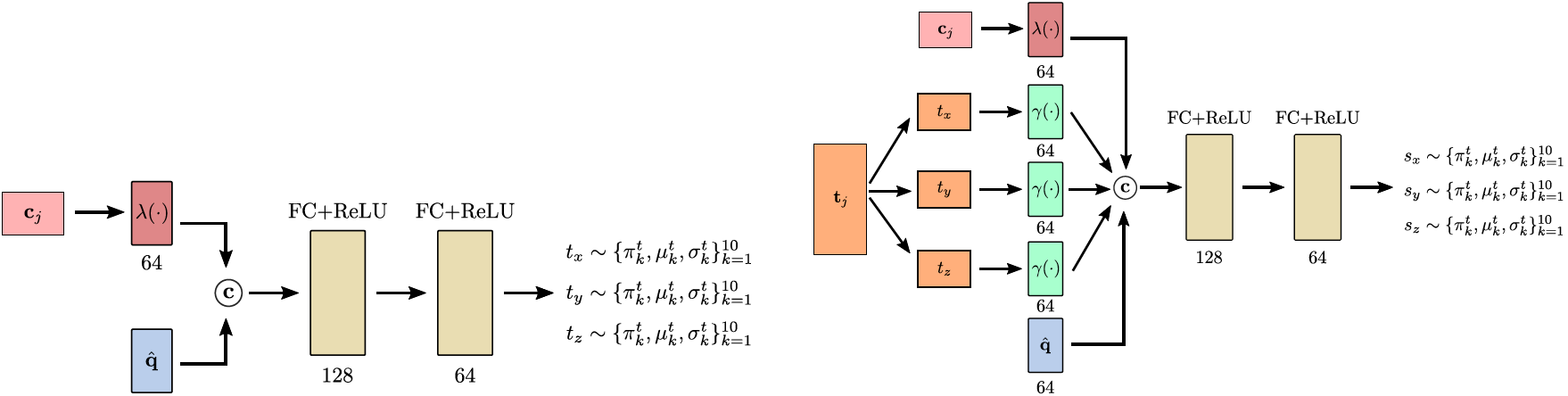
The attribute extractor consists of four MLPs that autoregressively predict the object attributes: object category first, followed by position, orientation and size. The MLP for the object category is a linear layer with 64 hidden dimensions that predicts $C$ class probabilities per object. The MLPs for the location, orientation and size predict the mean, variance and mixing coefficient for the $K$ logistic distributions for each attribute:
See Fig.3, ${\bf c}$ represents concatenation. Note that the attribute extractor for size in Fig.3 omits rotation ${\bf r}_j$.
Training
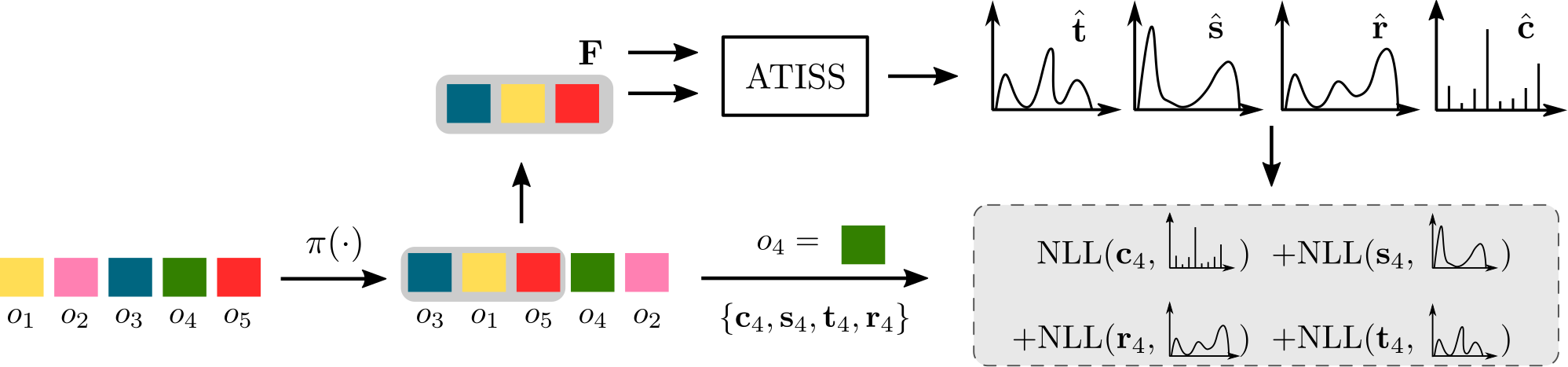
While training, given a scene with $M$ objects (coloured squares), we first randomly permute them and then keep the first $T$ objects (here $T = 3$). Conditioned on ${\bf C}$ and ${\bf F}$, the network predicts the attribute distributions of the next object to be added in the scene and is trained to maximize the log-likelihood of the $T +1$ object from the permuted scene.